Т. Бернерс-ЛИ, Н. Шэдболт. Рождение науки об Интернете
Изучение Всемирной паутины позволит более эффективно использовать информацию, предотвращать хищение личных данных, коренным образом изменить производство и управлять постоянно растущим числом сетевых сообществ
Об авторах
Сэр Тимоти Джон Бернерс-Ли (англ. Sir Timothy John «Tim» Berners-Lee; род. 8 июня 1955) — знаменитый британский учёный, изобретатель URI, URL, HTTP, HTML, изобретатель Всемирной паутины (совместно с Робертом Кайо) и действующий глава Консорциума Всемирной паутины. Автор концепции семантической паутины. Автор множества других разработок в области информационных технологий.
Главный литературный труд Бернерса-Ли — это книга «Плетя паутину: истоки и будущее Всемирной паутины» (англ. «Weaving the Web: Origins and Future of the World Wide Web», Texere Publishing, 1999, ISBN 0-7528-2090-7). В этой книге он рассказывает о процессе создания Паутины, её концепции и своём видении развития Интернета. В этом основополагающем труде автор говорит о нескольких важных принципах:
1. Возможность редактировать информацию Паутины не менее важна, чем возможность просто лазать по ней. В этом смысле Бернерс-Ли очень рассчитывает на концепцию WYSIWYG, хотя Wiki — это тоже шаг в нужном направлении.
2. Компьютеры могут быть использованы для «фоновых процессов», помогающих людям работать сообща.
3. Каждый аспект Интернета должен работать как паутина, а не как иерархия. В этом смысле очень неприятным исключением является система имён доменов (англ. Domain Name System, DNS), управляемая организацией ICANN.
4. Учёные-компьютерщики несут не только техническую ответственность, но и моральную.
Главный литературный труд Бернерса-Ли — это книга «Плетя паутину: истоки и будущее Всемирной паутины» (англ. «Weaving the Web: Origins and Future of the World Wide Web», Texere Publishing, 1999, ISBN 0-7528-2090-7). В этой книге он рассказывает о процессе создания Паутины, её концепции и своём видении развития Интернета. В этом основополагающем труде автор говорит о нескольких важных принципах:
1. Возможность редактировать информацию Паутины не менее важна, чем возможность просто лазать по ней. В этом смысле Бернерс-Ли очень рассчитывает на концепцию WYSIWYG, хотя Wiki — это тоже шаг в нужном направлении.
2. Компьютеры могут быть использованы для «фоновых процессов», помогающих людям работать сообща.
3. Каждый аспект Интернета должен работать как паутина, а не как иерархия. В этом смысле очень неприятным исключением является система имён доменов (англ. Domain Name System, DNS), управляемая организацией ICANN.
4. Учёные-компьютерщики несут не только техническую ответственность, но и моральную.
Найджел Шэдболт, профессор исследований искусственного интеллекта в Университете Саутгемптона, главный технолог компании Garlic Ltd, занимающейся Семантической паутиной, и бывший президент Британского компьютерного общества.
ОСНОВНЫЕ ПОЛОЖЕНИЯ
Неумолимый рост числа страниц и связей во Всемирной паутине порождает новые свойства, характерные для целостной системы, от социальных сетей до виртуальной кражи идентификационной информации, что преобразует общество.
Цель новой науки вебологии состоит в том, чтобы выяснить, как возникают новые свойства Паутины и как их можно использовать или держать под контролем для пользы обществу.
Уже делаются первые важные шаги. Последующие работы позволят решить многие важные вопросы, в частности защиты личной сферы и передачи полномочий.
С момента появления Всемирной паутины (World Wide Web, WWW) в середине 1990-х гг. число страниц в ней превысило 15 млрд., и они охватывают почти все стороны современной жизни. Сегодня от Интернета зависит работа все большего количества людей. Он совершил революцию в СМИ, банковском деле и здравоохранении. Правительства даже рассматривают возможность управления своими государствами с помощью Сети. Однако то, что Всемирная паутина — нечто большее, чем просто совокупность сайтов, осознают немногие. Возникли новые возможности, преобразившие общество. Электронная почта, обеспечив мгновенный обмен сообщениями, вызвала к жизни такие социальные сети, как Facebook. Возможность обмена документами способствовала возникновению веб-сайтов с общим доступом к файлам, таких как Napster, что в свою очередь привело к появлению порталов, создаваемых пользователями, в частности YouTube. А снабжение контента метками породило сетевые сообщества, имеющие совместный доступ ко всему — от новостей о концертах до советов по воспитанию детей.
Однако вопросами о том, как возникли эти новые свойства, какую пользу можно из них извлечь, какие еще могут появиться феномены и какое значение они будут иметь для человечества, занимались очень немногие исследователи. Изучение всех этих вопросов и является задачей новой отрасли науки — вебологии. История повторяется: сначала появились компьютеры, а уже затем наука о них — информатика, позволившая значительно усовершенствовать компьютеры. Как формальная дисциплина вебология возникла в ноябре 2006 г, когда мы и наши коллеги из Массачусетсского технологического института и Саутгемптонского университета в Англии объявили о начале проекта исследования Всемирной паутины (Web Science Research Initiative, WSRI). С тех пор ряды исследователей пополнили ведущие специалисты из 16 лучших университетов мира.
Новая отрасль науки занимается моделированием структуры WWW, выявлением архитектурных закономерностей, обеспечивших ее феноменальное развитие, выяснением, как взаимодействие людей через Интернет влияет на изменение норм общения. Ей предстоит выработать принципы, способные обеспечить дальнейший продуктивный рост Всемирной паутины, и справиться с такими сложными проблемами, как защита личной сферы и прав на интеллектуальную собственность. Для решения поставленных задач вебология будет обращаться к математике, физике, информатике, психологии, экологии, социологии, правоведению, политологии, экономике и другим наукам.
Разумеется, мы не способны предвидеть, каковы будут результаты исследований. В конечном итоге предстоит получить ответы на фундаментальные вопросы. Какие эволюционные структуры вызывают рост Всемирной паутины? Могут ли они перестать действовать? Как наступают переломные моменты, и можно ли влиять на данный процесс?
Первые достижения
Несмотря на то что вебология — еще очень молодая наука, уже первые исследования продемонстрировали важность работы в данном направлении. К концу 1990-х гг. поиск информации по ключевым словам в растущем числе страниц все чаще приводил к получению контента, не относящегося к делу. Основатели поисковой системы Google Ларри Пейдж (Larry Page) и Сергей Брин (Sergey Brin) поняли, что необходимо обеспечить приоритизацию результатов.
Несмотря на то что вебология — еще очень молодая наука, уже первые исследования продемонстрировали важность работы в данном направлении. К концу 1990-х гг. поиск информации по ключевым словам в растущем числе страниц все чаще приводил к получению контента, не относящегося к делу. Основатели поисковой системы Google Ларри Пейдж (Larry Page) и Сергей Брин (Sergey Brin) поняли, что необходимо обеспечить приоритизацию результатов.
Их важным достижением было осознание того, что значимость страницы лучше всего характеризуют количество и значимость связанных с нею других страниц. Трудность состояла в том, что часть этого определения является рекурсивной: значимость данной страницы определяется значимостью страниц, связанных с ней, а их значимость определяется значимостью страниц, связанных с ними. Пейдж и Брин разработали изящный математический способ представления этого свойства и создали алгоритм PageRank, который обеспечивает выдачу страниц в порядке убывания релевантности (соответствия).
Успех системы Google показывает, что важно понимать Сеть и совершенствовать ее. На решение этих задач и нацелена вебология. Всемирная паутина — это инфраструктура языков и протоколов, т.е. техническая структура. Однако возникающие свойства определяют принцип организации взаимосвязей контента. Некоторые из них нужны, и желательно предусмотреть их в системе. В частности, именно возможность связывания любой страницы с любой другой страницей делает Всемирную паутину эффективной как в локальном, так и в глобальном масштабах. Другие свойства, такие как возможность создания сайта с тысячами искусственных связей, генерируемых программными роботами (так называемыми фабриками связей) с единственной целью — повышения ранга сайта в поисковых системах, могут быть нежелательными, и их следует постараться исключить.
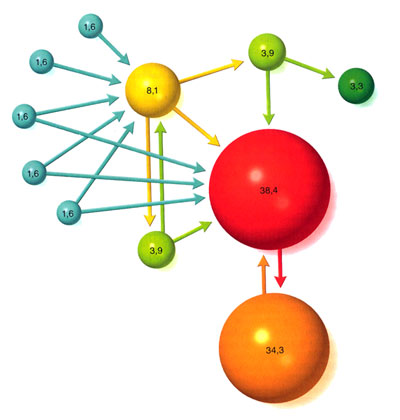
Алгоритм PageRank приоритизации результатов поиска для поисковой системы Google, сделавшей ее такой ценной, был одним из первых примеров того, какую пользу может принести вебология.
Представленная схема показывает, как взвешивания (по отношению к 100) важностей связей между 11 результатами поиска позволяют определить, какая страница наиболее релеванта
Другим ранним открытием, пришедшим из теории графов, было обнаружение того факта, что распределение числа связей узлов в Интернете подчиняется степенному закону. Во многих сетях число связей всех узлов примерно одинаковы, но в WWW небольшое число страниц имеет очень большое количество связей с другими страницами, а у очень большого числа страниц есть связи лишь с немногими другими страницами. Альберт-Ласло Барабаши (Albert-Laszlo Barabasi) из Северо-Западного университета и его коллеги дали таким сетям название безмасштабных (Барабашц А.-Л., Бонабо Э. Безмасштабные сети // ВМН, № 8, 2003). Многих это удивило: люди полагали, что все веб-страницы имеют близкие к среднему количества входящих и исходящих связей.
В безмасштабных сетях даже при удалении большинства узлов сохраняется вероятность того, что путь между одним из оставшихся узлов и любым другим все же будет существовать. Однако удаление даже сравнительно малого числа узлов с очень большим числом связей (концентраторов) ведет к существенному нарушению целостности сети. Результаты анализа имели важнейшее значение для организаций — будь то поставщики услуг связи или исследовательские лаборатории, —разрабатывающих маршрутизацию информации в Паутине, позволив им закладывать большую избыточность для балансировки трафика и повышения устойчивости сети против атак.
Углубление понимания природы безмасштабных сетей в результате анализа WWW подтолкнуло специалистов к исследованию других сетевых систем. Они нашли, что степенной закон распределения свойствен очень широкому кругу областей — от частоты цитирования научных работ до деловых союзов. Их исследования помогли Центрам контроля и профилактики заболеваемости США усовершенствовать свои модели распространения заболеваний, передаваемых половым путем, а биологам — лучше понять взаимодействия белков.
Научный анализ показал также, что Всемирная паутина характеризуется малой длиной путей и малой длиной слов. А Данкан Уотте (Duncan J. Watts) и Стивен Строгатц (Steven H. Strogatz) из Корнеллского университета еще в 1990-х гг. показали, что при всей огромности Сети для перехода с одной ее страницы на любую другую пользователю требуется не более 14 щелчков. Однако для полного понимания этих свойств нам нужно представить себе WWW как социальную сеть. В 1967 г. психолог Стэнли Милграм (Stanley Milgram) из Гарвардского университета предлагал жителям Омахи (штат Небраска) и Уичито (штат Канзас) отправить пакет некоему человеку в Бостоне, зная только его имя и некоторые общие приметы. Отправители должны были переслать пакет посреднику, который, как они полагали, может знать больше о том, как доставить пакет адресату, и может переслать пакет другому посреднику. В итоге до адресатов дошли 64 пакета из почти 300. Среднее число понадобившихся посредников составило шесть, что стало основой расхожей фразы «шесть шагов» («шесть степеней отдаления»).
Однако позднее Уотте, работающий сегодня в Колумбийском университете, попытался повторить эксперимент с сообщением по электронной почте, которое должно было быть передано через WWW, и обнаружил неудачи в поисках пути. В частности, если у посредника, получившего сообщение, не было мотива для передачи его дальше, путь обрывался. Однако даже малейший мотив улучшал положение.
Из этого следовало, что лишь одна структура — еще не все. Сети успешны только в свете действий, стратегий и восприятий задействованных в них людей. Чтобы понять, почему WWW имеет благоприятную структуру с короткими путями, нужно понять, почему люди, вносящие контент, связывают его с другими материалами. Фундаментальные аспекты формирования путей — это социальные побуждения: цели, желания, интересы и точки зрения. Чтобы понять Всемирную паутину, необходимо рассмотреть каждую мелочь в ней не только в ключе математики и информатики, но также социологии и психологии.
От микро до макро
Важное направление вебологии — изучение вопроса о том, каким образом небольшие технические новшества вызывают большие перемены в обществе. Яркий пример — возникновение блогосферы. Если первые веб-браузеры не предоставляли среднему пользователю простого способа «публикации» своих соображений, то к 1999 г. процесс облегчили блоговые программы. Блоггинг стал быстро распространяться, поскольку люди, обнародовав свои мысли и взгляды в Интернете, обнаружили единомышленников, а также возможность легко объединиться с ними в сообщество.
Важное направление вебологии — изучение вопроса о том, каким образом небольшие технические новшества вызывают большие перемены в обществе. Яркий пример — возникновение блогосферы. Если первые веб-браузеры не предоставляли среднему пользователю простого способа «публикации» своих соображений, то к 1999 г. процесс облегчили блоговые программы. Блоггинг стал быстро распространяться, поскольку люди, обнародовав свои мысли и взгляды в Интернете, обнаружили единомышленников, а также возможность легко объединиться с ними в сообщество.
Оценить масштаб блогосферы сколько-нибудь точно нелегко. В мае 2008 г. передовая машина поиска блогов Technorati, созданная Дэвидом Сифти (David Sifty), обнаружила во всем мире больше 112 млн сетевых дневников, но в это число входит лишь небольшая часть из тех 72 млн, которые предположительно имеются в Китае. Однако как бы то ни было, стремительный рост количества блогов нуждается в объяснении. Возможно, ему способствовало внедрение очень простых механизмов, особенно механизма TrackBack. Когда блоггер делает запись, где ссылается на другой блог или комментирует его содержимое, TrackBack помечает исходный блог «звонком», что позволяет исходному ресурсу выдать сводку всех комментариев к нему и связей с ним. В результате возникает «беседа», охватывающая несколько дневников, и быстро формируются сети лиц, интересующихся конкретными темами. И снова большие части структуры блогов оказываются связанными короткими путями, соединяющими не только блоги и блоггеров, но и темы и записи.

ПОСТРОЕНИЕ БОЛЕЕ БЕЗОПАСНОЙ ПАУТИНЫ
Понимание организации связей в WWW может выявить пути ее совершенствования. Многие сети довольно однородны (имеют "экспоненциальную структуру): их узлы, даже наиболее загруженные (оранжевые точки) и их ближайшие соседи (синие точки) имеют примерно одинаковое число как входящих, так и выходящих связей. Однако анализ, проведенный в Университете Нотр-Дам, показал, что WWW является безмасштабной сетью: небольшое число узлов (веб-сайтов) характеризуются многочисленными связями, а многие узлы имеют лишь небольшое число связей
Расцвет блоггинга побудил исследователей к созданию средств и методов измерений и массивов данных для изучения и отслеживания распространения тем по пространству сетевых дневников. Аналитик Мэтью Херст (Matthew Hurst) из Microsoft Live Labs собрал данные о взаимосвязях за шестинедельный период и построил схему наиболее активных тесно связанных между собой частей блогосферы. Эта схема показывает, что некоторые блоги исключительно популярны: их ежедневно посещает до 500 тыс. человек. Соединение такого сетевого ресурса с другим или упоминание последнего гарантирует возникновение к нему интенсивного трафика. На схеме видны также изолированные группы «узкопрофильных» энтузиастов, очень активно общающихся между собой, но почти не контактирующих с другими блоггерами.

БЛОГОСФЕРА имеет несколько структур влияния. Мэтью Херст проследил, как блоги связываются между собой. На схеме слева каждый блог представлен белым кружком или белой точкой. Немногие большие кружки - это очень популярные сайты. Блоги, связанные между собой многочисленными перекрёстными ссылками, образуют четко выраженные сообщества (выделены сиреневым цветом). Отдельные группы, часто сообщающиеся между собой, но редко с другими, образуют прямые линии на периферии схемы
При правильном использовании блогосфера может быть мощной средой распространения идей, анализа воздействия политических инициатив или оценки вероятности успеха нового продукта. В день появления на рынке долгожданного IP-телефона iPhone компании Apple ему было посвящено 1,4% публикаций в блогах. Очень важно понять, как такое распространение информации может изменить наше отношение к журналистике и комментариям. Какой механизм может гарантировать читателям блогов достоверность приводимых материалов? Вебология может предоставить способы проверки так называемого происхождения информации и предложить практические правила в отношении ее повторного использования. Именно этому посвящен проект Transparent Accountable Datamining Initiative Дэниела Уэйтцнера (Daniel Weitzner) из Массачусетсского технологического института.
Рождение Семантической паутины
Другим важным результатом исследований стало возникновение Семантической паутины (Semantic Web, SW) — сети данных в WWW. Одно из множества ее полезных свойств — более высокая вероятность получения конкретных ответов на поставленные вопросы. Сегодня на запрос сведений о подержанных автомобилях Toyota, предлагаемых на продажу в штате Массачусетс по цене до $8 тыс., поисковая система Google выдаст более 2 тыс. веб-страниц. При использовании же средств SW будет получена подробная информация о семи или восьми конкретных автомобилях с указанием цены, цвета, пробега и состояния каждого из них, сведений о владельце и о том, как купить автомобиль.
Инженеры разработали эффективные основы SW, прежде всего первичный язык Resource Description Framework (RDF), накладываемый поверх основного языка HTML и других протоколов, формирующих вебстраницы. RDF придает данным смысл с помощью наборов троек. Элементы каждой тройки подобны подлежащему, сказуемому и дополнению в предложении. Например, тройка может утверждать, что некто «икс» [подлежащее] является сестрой [сказуемое] «игрека» [дополнение]. А ряд троек может показать, что [автомобиль X] [есть] [Toyota], что [автомобиль X] [есть] [подержанный]; [автомобиль X] [стоит] [$7,5 тыс.], что [автомобиль X] [находится в] [Леноксе], и что [Ленокс] [находится в] [западном Массачусетсе]. В совокупности эти тройки позволяют заключить, что автомобиль X отвечает требованиям запроса. Такая простая система троек оказывается естественным способом описания большей части данных, обрабатываемых компьютерами. Каждый из трех элементов тройки — подлежащее, сказуемое и дополнение — определяется универсальным индикатором ресурсов (Universal Resource Identifier, URI) — адресом, очень похожим на используемые для веб-страниц. Таким образом, любой человек может определить новую концепцию или новую операцию, просто задав для нее URL.
По мере роста числа этих определений и взаимосвязей между ними специалисты и энтузиасты будут вырабатывать таксономии и онтологии: наборы данных, описывающие классы объектов и их взаимоотношения. Такие наборы помогут компьютерам во всем мире находить и представлять именно искомую информацию.
Многочисленные группы уже сегодня создают структуры SW, особенно в биологии и здравоохранении [см.: Нойманн Э., Стивенс С., Фегенбаум Л., Херман И., Хонгзермайер Т. Семантическая сеть в действии // ВМН, № 3, 2008). В конференции по семантической технологии в Сан-Хосе в мае 2008 г. приняло участие больше тысячи человек. Вебология открывает перспективы создания более мощных средств определения, связывания и интерпретации данных.
Мир Wiki (вики) — хороший пример того, каким полезным может быть такое использование взаимосвязанных данных. К маю 2008 г. в сетевой энциклопедии Wikipedia, создаваемой людьми со всего мира, уже содержалось больше 2,3 млн статей на английском языке. Статьи содержат как обычный текст, так и информационные шаблоны с наборами фактов. Сегодня существует больше 700 тыс. таких шаблонов на английском языке, и программисты придумывают способы их поиска. Один из таких проектов, DBpedia, начали Крис Бицер (Chris Bizer) и его коллеги из Свободного университета Берлина и Лейпцигского университета в Германии. Они разработали инструмент с тем же названием, какое используется в методах SW для запроса информационных боксов. Этот инструмент позволяет, например, найти всех теннисистов, живущих в Москве, или узнать имена мэров всех городов США, лежащих на высоте больше 1000 м.
Естественно, хотелось бы иметь подобный инструмент для всей WWW, но его разработка потребует, чтобы все большее количество данных в ней представлялось в виде связанных наборов RDF. Между тем выясняется, что структура связей DBpedia подчиняется тому же степенному закону, что и WWW. Если в Паутине документов некоторые страницы имеют более высокий ранг, то таким же будет и положение для данных в SW. В то же время Одед Нов (Oded Nov) из Политехнического института Нью-Йоркского университета в своих исследованиях начинает прояснять вопрос о том, почему участники Wikipedia помещают в нее свои вклады, и что движет их действиями. Обнаруженные психологические мотивы помогут понять, как поощрять людей делать вклады в SW.
Будущие задачи
Разумно предположить, что вебология позволит построить более совершенную WWW. К сожалению, мы не все знаем о том, что представляет собой сама вебология, поэтому важной ее частью должен быть поиск наиболее эффективных концепций, которые помогли бы развиваться ей как науке. Возможно, источником идей станет ее междисциплинарный характер. Например, полезным может оказаться такое биологическое понятие, как пластичность. Мозг и нервная система растут и приспосабливаются к изменениям условий в течение всей нашей жизни, создавая и разрывая связи между нейронами — клетками мозга, играющими роль узлов в нашей нервной сети. Изменения соединений происходят в ответ на деятельность сети, включая обучение, отсутствие использования и старение.
Разумно предположить, что вебология позволит построить более совершенную WWW. К сожалению, мы не все знаем о том, что представляет собой сама вебология, поэтому важной ее частью должен быть поиск наиболее эффективных концепций, которые помогли бы развиваться ей как науке. Возможно, источником идей станет ее междисциплинарный характер. Например, полезным может оказаться такое биологическое понятие, как пластичность. Мозг и нервная система растут и приспосабливаются к изменениям условий в течение всей нашей жизни, создавая и разрывая связи между нейронами — клетками мозга, играющими роль узлов в нашей нервной сети. Изменения соединений происходят в ответ на деятельность сети, включая обучение, отсутствие использования и старение.
Подобным образом разрушаются и создаются соединения во Всемирной паутине. Вебология может использовать также возможности протоколов, разъединяющих веб-узлы, если между ними нет активного трафика. Будет ли такая сеть работать эффективнее?
В WWW существуют аналоги таких понятий, как динамика популяции, пищевые цепи, потребители и производители. Возможно, что методы и модели, разработанные для экологии, помогут понять цифровую экосистему WWW, подверженную повреждению в результате единичного крупного события (аналогичного урагану) или незначительной, но непрерывной эрозии (аналогичной воздействию инвазивных видов).
Необходимо исследовать также ряд юридических аспектов. Законы, касающиеся интеллектуальной собственности и авторских прав на цифровые материалы, уже обсуждаются. В виртуальных средах, таких как Second Life, поднимаются интересные проблемы. Например, можно ли переносить действие законов и норм на цифровые миры, где миллионы людей вносят свою лепту в уже существующий контент? Другой вопрос: можно ли создать особые правила использования этого контента? Одна такая структура, Creative Commons, позволяет авторам, ученым, художникам и преподавателям снабжать свои творческие работы пометками, указывающими на ограничения их использования или отсутствие таких ограничений. Очень важно, что такие метки предоставляют также RDF-данные, определяющие лицензию, что позволяет легко автоматически отыскивать работы и узнавать условия их использования. Вебология может определить, влияют ли традиционные лицензии на распространение информации.
Еще одна область, использование которой может принести пользу — социология. В частности, нужны исследования для предоставления пользователям более эффективных средств определения достоверности материалов, имеющихся на сайте. Как узнать, можно ли доверять размещенной на сайте информации? Всемирная паутина первоначально задумывалась как инструмент для исследователей, которые безоговорочно доверяют друг другу, поэтому в ней не были предусмотрены мощные средства защиты. Последствия мы ощущаем по сей день.
Все это значит, что при взаимодействиях во Всемирной паутине нужно провести большую работу по созданию уровней доверия и проверки происхождения информации. Объединение цифровой и физической личностей откроет перед нами новые возможности, подобно тому, как интеграция финансовых, социальных и образовательных услуг расширила их спектр для каждого из нас. Но при этом возникает угроза кражи личной информации, киберслежения, кибермошенничества и цифрового шпионажа. Вебология может помочь развить достоинства Сети и свести на нет ее недостатки.
Чтобы можно было использовать весь богатый потенциал WWW до конца, нужно будет разобраться и со многими другими вопросами. Как влияют социальные нормы на возникающие возможности? Как обеспечить в Сети защиту частной сферы, прав на интеллектуальную собственность и безопасность? Какие тенденции могут раздробить Паутину?
Над некоторыми из этих вопросов работает множество людей. Вебология может свести их усилия воедино и сформировать новые представления. Чтобы понять природу WWW и пути ее дальнейшего развития в XXI в. и далее, необходимо подготовить исследователей, практиков и пользователей в широком диапазоне областей и тем.
Перевод: И.Е. Сацевич
ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
• Exploring Complex Networks. Steven H. Strogatz in Nature, Vol. 410, pages 268- 276; March 8, 2001.
• The Semantic Web Revisited. Nigel Shadbolt, Tim Berners-Lee and Wendy T. Hall in IEEE Intelligent Systems, Vol. 21, No. 3, pages 96-101; May/June 2006.
• Creating a Science of the Web. Tim Berners-Lee, Wendy T. Hall, James W. Hendler, Nigel Shadbolt and Daniel Weitzner in Science, Vol. 313, pages 769-771; August 11, 2006.
• Creating a Science of the Web. Tim Berners-Lee, Wendy T. Hall, James W. Hendler, Nigel Shadbolt and Daniel Weitzner in Science, Vol. 313, pages 769-771; August 11, 2006.
• Googles PageRank and Beyond: The Science of Search Engine Rankings. Amy N. Langville and Carl D. Meyer. Princeton University Press, 2006.
• Web Science: an Interdisciplinary Approach to Understanding the Web. James Hendler, Nigel Shadbolt, Wendy T. Hall, Tim Berners-Lee and Daniel Weitzner in Communications of the ACM, Vol. 51, No. 1, pages 60-69; July 2008.
"В мире науки", № 1, 2009






 Издательство «Свиньин и сыновья» выпустило несколько сотен самых разных по жанру, объему и авторам, но неизменно высококультурных изданий
Издательство «Свиньин и сыновья» выпустило несколько сотен самых разных по жанру, объему и авторам, но неизменно высококультурных изданий





